
Det har väl inte gått en dag de senaste åren utan att man hört talas om någon form av AI. Störst uppmärksamhet har ChatGPT samt andra generativa lösningar som Dall-E fått. Dessa implementationer har inneburit ett stort steg framåt när det gäller att få ut AI till de stora massorna.
Om du hade berättat för någon för ett par år sedan att vi idag skulle ha möjlighet att bara surfa in på en sida och skapa helt nya unika bilder enbart baserat på text-instruktioner, eller att få utförliga och korrekta (?) svar på komplicerade frågeställningar, så hade de nog tittat konstigt på dig.
AI finns redan idag i en stor del av vår tillvaro.
Men vad är egentligen AI, Machine Learning och andra uttryck som man hör talas om i dessa sammanhang?
Jag tänkte ta det mest kända exemplet ChatGTP och bryta ner det i de olika områden och discipliner som det spänner över, från det mest generella området AI till den specifika tillämpningen ChatGPT, se illustration här intill.
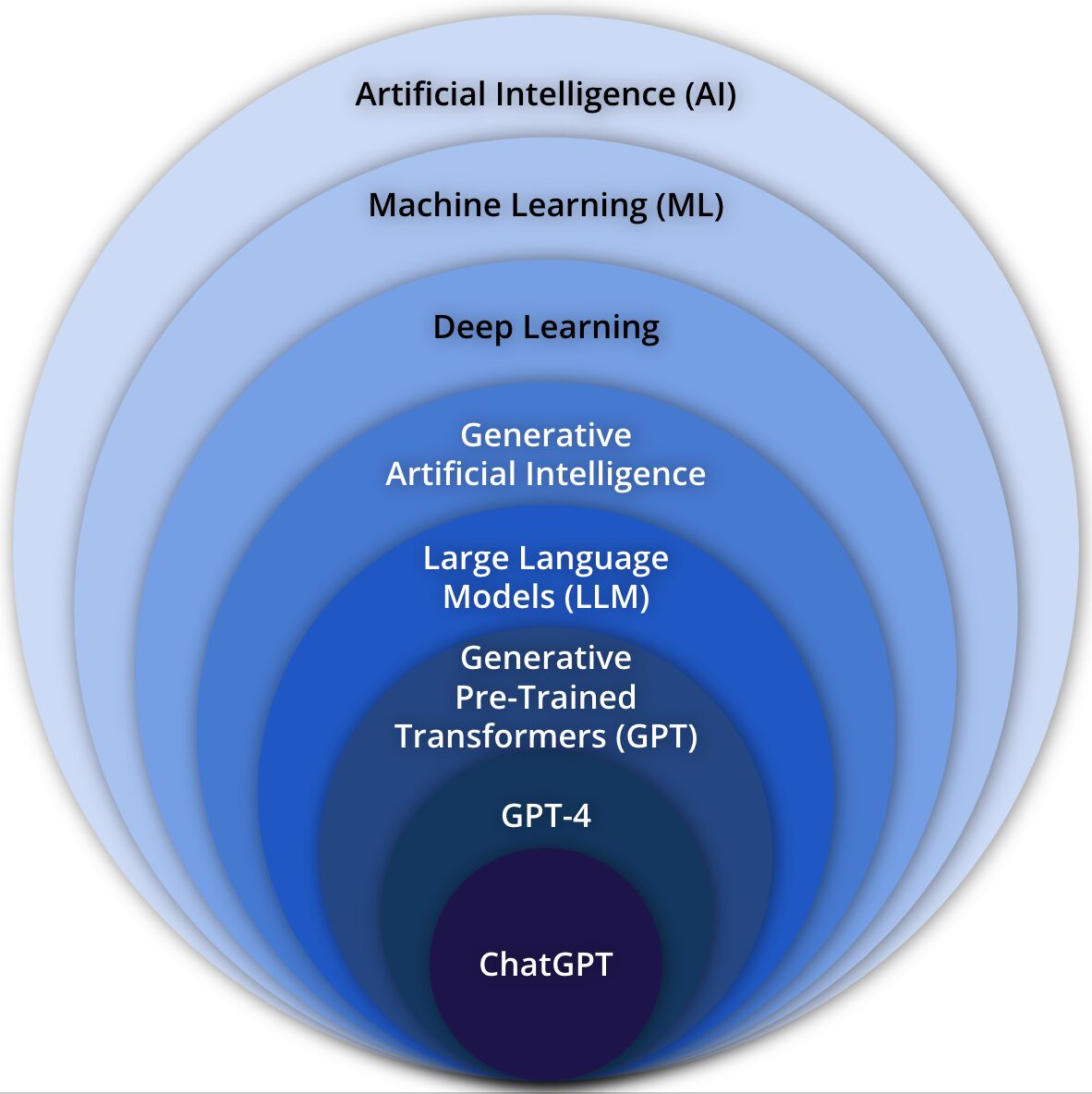
Articifial Intelligence
Artificial Intelligence (AI) är ett brett område som fokuserar på att skapa system och maskiner som är kapabla att utföra uppgifter som normalt kräver mänsklig intelligens.
Exempel kan vara ett beslutsstöd/expert-system enligt bilden härintill
Här finns ingen egentlig intelligens utan det handlar mer om en maskin som ger svar utifrån förutbestämda regler och förutsättningar.
Machine Learning
Machine Learning (ML) är en delmängd av AI som innefattar utvecklingen av algoritmer och modeller som möjliggör för datorer att dra lärdom av data, göra förutsägelser och tillochmed fatta beslut.
Dock krävs ofta mänsklig hjälp för att träna modellerna.
Att det inte blir rätt alla gånger illustreras av bilden intill, där Microsofts verktyg för bildigenkänning ansåg att tre av bilderna varken var muffins eller verkliga chihuahuas utan istället uppstoppade mjukisdjur.

Deep learning
Deep Learning (DL) är en underavdelning inom ML som använder artificiella neurala nätverk med multipla lager för att modellera mer komplexa mönster och få bättre resultat än traditionell ML. Exempel på DL är TensorFlow-ramverket som möjliggör att realisera DL-modeller med hjälp av grafikprocessorer (GPU).
Generative Artificial Intelligence
Generative Artificial Intelligence (GenAI) är en gren inom AI dedikerad till att skapa system som kan generera nytt innehåll, såsom bilder, text och musik.
Large Language Models
Large Language Models (LLM) representerar en kategori av AI modeller som inkluderar GPT-liknande modeller och andra liknande språkfokuserade modeller, oftast med ett väldigt stort antal parametrar.
Generative Pre-Trained Transformers
Generative Pre-Trained Transformers (GPT) är en speciell typ av GenAI modell som tillämpar en transformerings-arkitektur och är för-tränad på enorma mängder av text-data för att kunna generera människoliknande text.
GPT4
GPT4 är en specifik version av GPT-serien av modeller, välkänd för sin förmåga att både förstå och generera människoliknande språk jämfört med tidigare versioner.
ChatGPT
ChatGTP är en enskild instans, med tillhörande användargränsnitt, av en LLM baserad på GPT-arkitekturen. Den är designad för att generera människoliknande text-svar i en konversationsbaserad kontext.
Den finns lätt tillgänglig på nätet för alla användare i världen.
Detta är ju fantastiskt, eller hur?
Vi kan få hjälp av automatiserade intelligenta system för att underlätta både vårt yrkesliv och vår vardag. Såklart borde vi omfamna detta?
Nja…
Problemet är just att Artificiell Intelligens inte är lika med Mänsklig Intelligens. Mänsklig intelligens är mycket mer komplex än vad man hittills kunnat skapa modeller för. Den innefattar samvete, etik och moral, erfarenhet, känslor, riskbedömningar, målinriktning med flera ”mjuka värden” som är svåra att beskriva.
Det finns även ett problem avseende att det är människor som skapat modellerna, men i vissa fall med DL eller GenAI/LLM så låter man modellerna träna sig själva, vilket leder till att man inte kan utröna hur modellen faktiskt kom fram till sitt svar.
Om man är lite dystopiskt lagd kan man säga att algoritmerna fått eget liv och är på god väg mot att bli ”self-aware” i stil med Skynet i Terminator-filmerna.
Men rätt tillämpat så är AI-baserade lösningar ett otroligt effektivt stöd.
Till exempel inom vården, där man kan ha en simpel statisk AI-modell som väger samman massvis med parametrar och testvärden för att avgöra exempelvis risk för cancer eller hjärt-kärl-sjukdomar.
Här briljerar AI genom att helt outtröttligt kunna korrelera enorma datamängder som en människa aldrig hade klarat av.
Vi kan även gå ett steg längre och involvera bild-analys av röntgenbilder på misstänkta tumörer. En ML/DL-modell är otroligt mer pricksäker på att hitta tumörer i ett tidigt skede jämfört med en mänsklig läkare.
Även inom IT-världen har AI/ML använts under flera år.
Bland annat för att upptäcka skadlig kod, även om den är tidigare okänd. Genom mönsterigenkänning och beteendeanalys kan man göra tämligen exakta bedömningar av aldrig tidigare sedd kod.
Även GenAI används i IT-relaterade lösningar, speciellt inom SIEM/SOAR/SOC-lösningar. Dels för att hjälpa till att identifiera och korrelera säkerhetsrelaterade händelser, men även på senare tid för att berika händelser och ge rekommendationer till SOC-personal, exempelvis
Fortinet Advisor som berikar FortiSIEM och FortiSOAR och även ger operatören möjlighet att ställa frågor och få förklaringar.
MEN..
Här börjar vi närma oss ett av problemen med AI, speciellt när det gäller ML/DL och LLM. Dessa modeller måste tränas med enorma mängder data för att kunna fungera.
Hur säkerställer vi att träningsdata dels är komplett och även helt neutralt.
De flesta av oss vill säkert säga att de är neutrala, opåverkade och fördomsfria, men så är det tyvärr sällan. Vi är färgade av en mängd olika saker.
Denna ”bias” förs över till AI-modellerna och leder till att svaren och besluten förvrängs, speciellt om man har en modell som tränar sig själv, antingen baserat på resultat eller input från användare. Det finns många exempel på hur enkla chat-bots har blivit ”kapade” av illasinnade användare. De märkte att man kunde gradvis påverka hur svaren genererades genom att ställa riktade frågor. Helt plötsligt hade man en chat-bot som ”tänkte” rasistiskt.
Intressant artikel om bias: https://digiteket.se/inspirationsartikel/bias-eller-du-ar-inte-sa-objektiv-som-du-tror/
Som tur är så är många medvetna om riskerna med att släppa AI helt fritt, samt att blint lita på det som en modell spottar ur sig.
Man har till exempel redan tagit fram en topp-tio lista över sårbarheter i LLM, likt Web-sårbarheter.
Men helt klart är att det måste till reglering av AI-tekniken och dess användning.
Hur ska upphovsrätten hanteras?
Här har redan många innehålls-skapare reagerat mot att deras data använts för att träna AI-modeller.
Hur ska man kunna kvalitetssäkra eller kunna lita på en text, en bild eller en video faktiskt är äkta? Möjligtvis kan ett slags ursprungsmärkning eller källhänvisning tas fram.
En intressant aspekt av GDPR är att lagstiftningen avseende att man som individ har rätt att få sin data borttagen även gäller för AI-modeller. Dock är det fortfarande oklart hur det skulle gå till i praktiken.
Avslutningsvis
Eftersom dessa system består av mjukvara som helt eller delvis skapats av människor, så finns det redan idag kända sårbarheter, och fler lär upptäckas.
Är du som jag teknik-nörd kan du läsa nedan, en djuplodande och teknisk rapport om hur man kan gömma skadligt eller felaktigt beteende inuti en LLM och undgå upptäckt: https://arxiv.org/pdf/2401.05566.pdf
Till sist, för att besvara frågeställningen i rubriken.
”AI – Frälsare eller Förgörare?”
Svaret får bli det klassiska jurist/advokat-svaret, ”Det beror på…”
/Johan Hillström
